自前画像を使ったセマンティックセグメンテーションの実装_推論編(FusionNet)
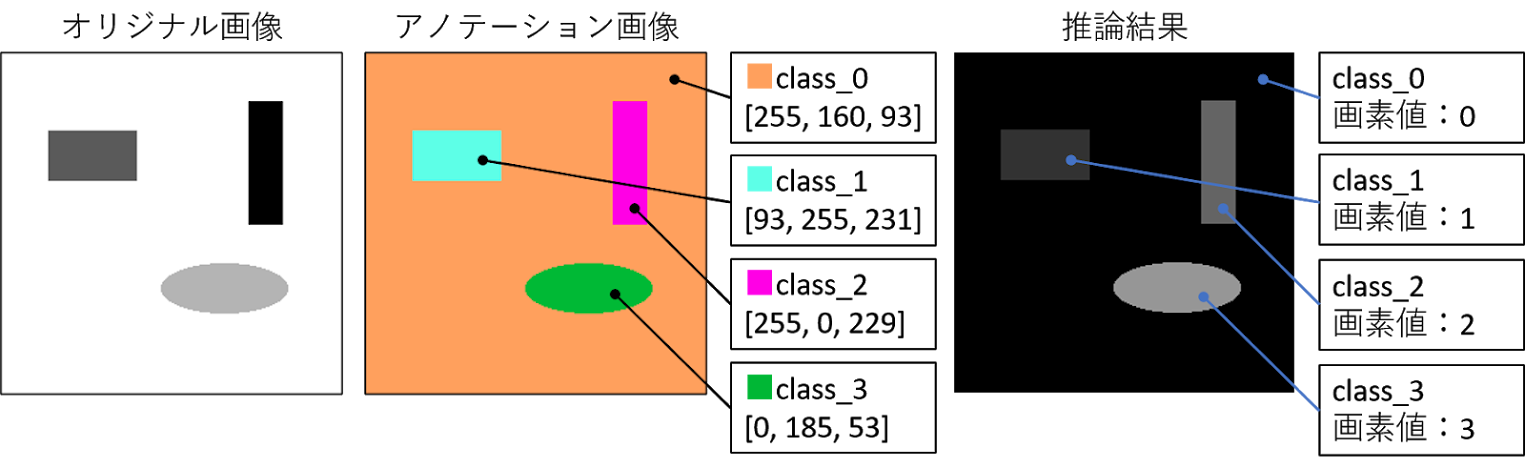
前回 の続きで、FusionNetというネットワークを使って、自前の画像でセマンティックセグメンテーションの推論を行うコードを作成してみたので紹介します。 このコードは google drive にも公開しています。 google colabで実行する際は、ディレクトリのマウント等を忘れないでください。 やり方は こちら です。 作成したコード import numpy as np import matplotlib.pyplot as plt import os import image from PIL import Image import glob import torch import torch.nn as nn import torch.utils as utils import torch.nn.init as init import torch.utils.data as data from torch.utils.data import DataLoader, random_split import torchvision.utils as v_utils import torchvision.datasets as dset import torchvision.transforms as transforms from torch.autograd import Variable from torchsummary import summary from torchvision import datasets from keras.preprocessing.image import load_img, save_img, img_to_array, array_to_img device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # Assume that we are on a CUDA machine, then this should print a CUDA device: print(device) batch_size = 1 img_size = 256 input_ch = 1 targ...