自前画像を使ったセマンティックセグメンテーションの実装_推論編(FusionNet)
前回の続きで、FusionNetというネットワークを使って、自前の画像でセマンティックセグメンテーションの推論を行うコードを作成してみたので紹介します。
このコードはgoogle driveにも公開しています。
google colabで実行する際は、ディレクトリのマウント等を忘れないでください。
やり方はこちらです。
作成したコード
import numpy as np
import matplotlib.pyplot as plt
import os
import image
from PIL import Image
import glob
import torch
import torch.nn as nn
import torch.utils as utils
import torch.nn.init as init
import torch.utils.data as data
from torch.utils.data import DataLoader, random_split
import torchvision.utils as v_utils
import torchvision.datasets as dset
import torchvision.transforms as transforms
from torch.autograd import Variable
from torchsummary import summary
from torchvision import datasets
from keras.preprocessing.image import load_img, save_img, img_to_array, array_to_img
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assume that we are on a CUDA machine, then this should print a CUDA device:
print(device)
batch_size = 1
img_size = 256
input_ch = 1
target_class = 4
data_dir = sorted(glob.glob("train/original/*.png"))
if input_ch ==3 :
color="rgb"
else:
color="grayscale"
def data_loader(org_path,color):
org_data = []
for m in range(len(org_path)):
#print(org_path[m])
org_img = load_img(org_path[m],color_mode=color)
org_img = img_to_array(org_img)/255
org_data.append(org_img)
org_data = np.array(org_data)
return org_data
#modelの構築
#inputは256*256
def conv_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.Conv2d(in_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def conv_trans_block(in_dim,out_dim,act_fn):
model = nn.Sequential(
nn.ConvTranspose2d(in_dim,out_dim, kernel_size=3, stride=2, padding=1,output_padding=1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def maxpool():
pool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
return pool
def conv_block_3(in_dim,out_dim,act_fn):
model = nn.Sequential(
conv_block(in_dim,out_dim,act_fn),
conv_block(out_dim,out_dim,act_fn),
nn.Conv2d(out_dim,out_dim, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_dim),
)
return model
class Conv_residual_conv(nn.Module):
def __init__(self,in_dim,out_dim,act_fn):
super(Conv_residual_conv,self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
act_fn = act_fn
self.conv_1 = conv_block(self.in_dim,self.out_dim,act_fn)
self.conv_2 = conv_block_3(self.out_dim,self.out_dim,act_fn)
self.conv_3 = conv_block(self.out_dim,self.out_dim,act_fn)
def forward(self,input):
conv_1 = self.conv_1(input)
conv_2 = self.conv_2(conv_1)
res = conv_1 + conv_2
conv_3 = self.conv_3(res)
return conv_3
class FusionGenerator(nn.Module):
def __init__(self,input_nc, output_nc, ngf):
super(FusionGenerator,self).__init__()
self.in_dim = input_nc
self.out_dim = ngf
self.final_out_dim = output_nc
act_fn = nn.LeakyReLU(0.2, inplace=True)
act_fn_2 = nn.ReLU()
# encoder
self.down_1 = Conv_residual_conv(self.in_dim, self.out_dim, act_fn)
self.pool_1 = maxpool()
self.down_2 = Conv_residual_conv(self.out_dim, self.out_dim * 2, act_fn)
self.pool_2 = maxpool()
self.down_3 = Conv_residual_conv(self.out_dim * 2, self.out_dim * 4, act_fn)
self.pool_3 = maxpool()
self.down_4 = Conv_residual_conv(self.out_dim * 4, self.out_dim * 8, act_fn)
self.pool_4 = maxpool()
# bridge
self.bridge = Conv_residual_conv(self.out_dim * 8, self.out_dim * 16, act_fn)
# decoder
self.deconv_1 = conv_trans_block(self.out_dim * 16, self.out_dim * 8, act_fn_2)
self.up_1 = Conv_residual_conv(self.out_dim * 8, self.out_dim * 8, act_fn_2)
self.deconv_2 = conv_trans_block(self.out_dim * 8, self.out_dim * 4, act_fn_2)
self.up_2 = Conv_residual_conv(self.out_dim * 4, self.out_dim * 4, act_fn_2)
self.deconv_3 = conv_trans_block(self.out_dim * 4, self.out_dim * 2, act_fn_2)
self.up_3 = Conv_residual_conv(self.out_dim * 2, self.out_dim * 2, act_fn_2)
self.deconv_4 = conv_trans_block(self.out_dim * 2, self.out_dim, act_fn_2)
self.up_4 = Conv_residual_conv(self.out_dim, self.out_dim, act_fn_2)
# output
self.out = nn.Conv2d(self.out_dim,self.final_out_dim, kernel_size=3, stride=1, padding=1)
self.out_2 = nn.Tanh()
# initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
def forward(self,input):
down_1 = self.down_1(input)
pool_1 = self.pool_1(down_1)
down_2 = self.down_2(pool_1)
pool_2 = self.pool_2(down_2)
down_3 = self.down_3(pool_2)
pool_3 = self.pool_3(down_3)
down_4 = self.down_4(pool_3)
pool_4 = self.pool_4(down_4)
bridge = self.bridge(pool_4)
deconv_1 = self.deconv_1(bridge)
skip_1 = (deconv_1 + down_4)/2
up_1 = self.up_1(skip_1)
deconv_2 = self.deconv_2(up_1)
skip_2 = (deconv_2 + down_3)/2
up_2 = self.up_2(skip_2)
deconv_3 = self.deconv_3(up_2)
skip_3 = (deconv_3 + down_2)/2
up_3 = self.up_3(skip_3)
deconv_4 = self.deconv_4(up_3)
skip_4 = (deconv_4 + down_1)/2
up_4 = self.up_4(skip_4)
out = self.out(up_4)
out = self.out_2(out)
#out = torch.clamp(out, min=-1, max=1)
return out
fusion = nn.DataParallel(FusionGenerator(input_ch,target_class,16)).cuda() #(3,4,3) = (input_ch,final_output_ch,z)
summary(fusion,(input_ch,img_size,img_size))
checkpoint = torch.load('model/fusion_499.pkl')
fusion.load_state_dict(checkpoint['model_state_dict'])
#optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
fusion.eval()
for m in range(len(data_dir)//batch_size):
x_train = data_loader(data_dir[m*batch_size:m*batch_size+batch_size],color=color)
x_train = x_train.transpose(0,3,1,2)
x_train = torch.from_numpy(x_train.astype(np.float32)).clone().cuda()
x = Variable(x_train).cuda()
y = fusion.forward(x)
y = y.to('cpu').detach().numpy().copy()
y_numpy = y.transpose(0,2,3,1)
y_numpy = np.argmax(y_numpy,axis=3)
y_numpy = y_numpy.reshape(img_size,img_size)
y_numpy = Image.fromarray(np.uint8(np.asarray(y_numpy)) , 'L')
#print(os.path.split(data_dir[m])[1])
y_numpy.save('result/'+os.path.split(data_dir[m])[1])
コードの使用方法の解説
ポイントは、下記の部分のコードに学習時の設定をそのまま反映することです。違う値を入れるとエラーになるはずです。
※batch_sizeだけは1にしないでください。
batch_size = 1
img_size = 256
input_ch = 1
target_class = 4
data_dir = sorted(glob.glob("train/original/*.png"))さらに、次のコードで学習時に保存したpklファイルを読み込んでください。
checkpoint = torch.load('model/fusion_499.pkl')
fusion.load_state_dict(checkpoint['model_state_dict'])
#optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']するとresultのフォルダに入力画像と同名の推論結果が保存されます。
(フォルダは学習前に作っておいてください)
学習結果について
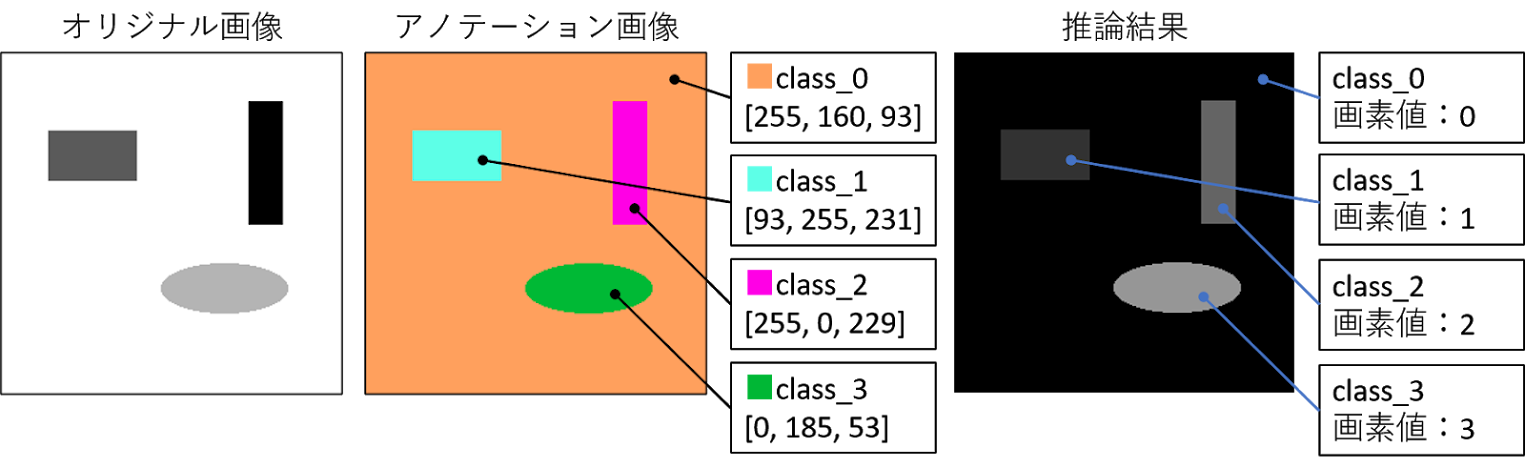
学習編の記事にも示しましたが、下図のような結果が得られます。

推論結果はグレースケール画像になりますので、各自で色を変更してください!
(アノテーション画像の配色にするコードを書くのがめんどくさくて諦めちゃいました・・・すいません。)
Stainless Steel Magnets - titanium arts
返信削除Ironing the Stainless Steel Magnets (4-Pack). Made in Germany. 토토 사이트 The Titanium Arts Stainless Steel aprcasino Magnets are an alloy made kadangpintar of titanium ring steel in stainless bsjeon.net steel